
Most enterprise AI initiatives do not fail because the model is “not good enough.” They fail because the surrounding system is not designed to survive production realities: messy data, shifting business rules, security constraints, uptime expectations, and cost limits. That gap is now measurable at scale. Gartner predicts that through 2026, organizations will abandon 60% of AI projects that are not supported by AI-ready data. Separately, IDC research (with Lenovo) found that 88% of observed AI proof-of-concepts did not reach widescale deployment, and that for every 33 AI POCs launched, only four graduated to production.These are not “model problems.” They are architecture and operating model problems.
This article breaks down why so much AI stops at demo, and the production-ready AI architecture patterns that consistently separate prototypes from scalable, reliable systems.
Why AI Projects Get Stuck at the Demo Stage
Most AI projects stall at the demo stage because they are built to prove technical feasibility, not to survive production conditions. A demo optimizes for speed and visible accuracy on controlled data. Production demands reliability across changing inputs, continuous operation, and business accountability. The gap between these two environments is architectural, not algorithmic.
The first failure point is data. AI pilots often rely on static, curated datasets, while production systems depend on live pipelines with evolving schemas and uneven data quality. Gartner estimates that through 2026, 60% of AI projects will be abandoned due to the lack of AI-ready data, including the infrastructure required to validate, monitor, and govern data at scale. When models trained on clean snapshots meet real-world data flows, performance degrades in ways that are difficult to detect and even harder to correct without production-grade data architecture.
A second issue is how success is measured. Demo success is usually defined by model metrics. Production success is defined by system behavior: latency, failure handling, uptime, and the ability to respond safely when assumptions break. Studies of failed AI initiatives show that organizations frequently underestimate these operational demands, treating deployment as an extension of experimentation rather than as a distinct engineering problem. Without observability and control mechanisms, teams cannot manage AI behavior once it is exposed to real users and workflows.
Finally, many AI projects reach a structural dead end when security, governance, and cost constraints are introduced late in the process. Demos often operate with broad access and minimal controls that cannot pass enterprise review. At the same time, inference costs that appear manageable in pilots grow rapidly under real traffic. Gartner projects that over 40% of agentic AI initiatives will be canceled by 2027 due to escalating costs and unresolved risk issues.
In short, AI fails to move beyond demo not because models lack capability, but because systems are not designed for production realities. Without architecture that accounts for data volatility, operational reliability, and economic constraints from the outset, AI remains impressive in prototypes yet unfit for sustained deployment.
What Production-Ready AI Architecture Means
Production-ready AI architecture is not “a model behind an API.” It is an end-to-end system that can:
Ingest and validate data continuously (not just once)
Deploy models safely with rollback paths and controlled blast radius
Observe behavior across data quality, model performance, and user impact
Govern access and usage with auditability and compliance controls
Scale predictably under cost and latency constraints
A useful way to frame it is this: production AI is a socio-technical system. The architecture must handle not only inference, but also accountability, change management, and operational feedback loops.
This framing aligns with what broader adoption data suggests. Stanford’s AI Index reports that 78% of organizations reported using AI in 2024, up from 55% the year before.Usage is mainstream; production maturity is not. The competitive edge is increasingly determined by architecture and operating discipline, not by model novelty alone.
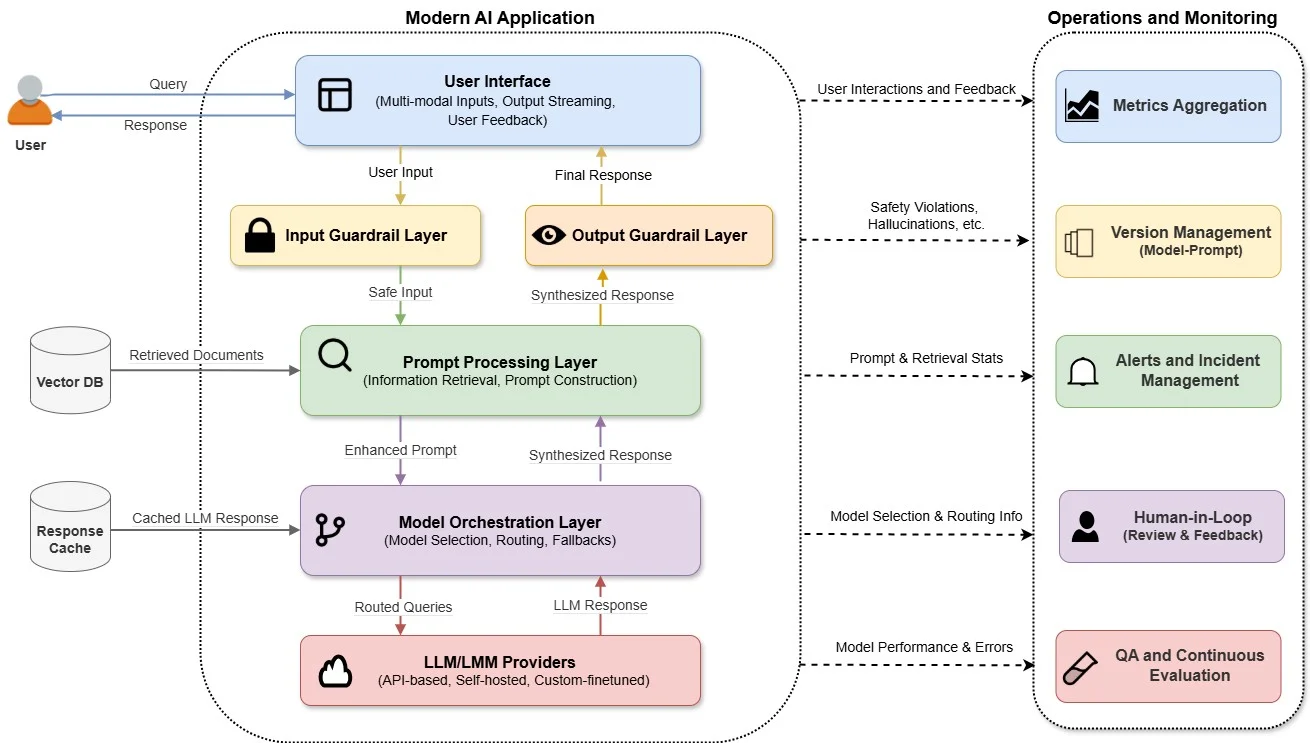
Production-ready AI system architecture with guardrails, orchestration, observability, and human-in-the-loop (Source: AWS Architecture Reference)
Core Architecture Patterns for Scalable AI Applications
A key reason so many AI initiatives fail to scale is that the initial architecture is built for proof-of-concept, not continuous production operation. Many enterprises report that while pilots perform well, only a small fraction consistently deliver business value at scale. Surveys suggest up to 88% of AI proofs-of-concept never transition into production systems, meaning fewer than 1 in 8 prototypes become operational capabilities.To close this gap, scalable AI systems require well-architected patterns that address data volatility, operational reliability, business risk, and cost discipline not just model performance.
1. Decoupled Model Serving for Independent Lifecycle Management
In many AI pilots, the model is embedded directly into application logic. This creates a fragile dependency: every model update becomes an application release, and every application change risks altering model behavior. While this approach accelerates demos, it becomes a structural liability in production.
Decoupled model serving separates inference into a dedicated, versioned service layer with explicit deployment and rollback controls. This pattern matters because AI behavior changes more frequently than business logic. Models are retrained, prompts evolve, features shift, and inference configurations are tuned continuously. Without decoupling, organizations are forced into slow, high-risk release cycles that discourage iteration and increase downtime.
At scale, this separation enables two critical production capabilities. First, it limits blast radius: a model regression can be isolated and rolled back without destabilizing downstream systems. Second, it enables parallel velocity: product teams ship features while ML teams improve models independently. This architectural boundary is one of the clearest dividing lines between AI systems that stagnate after launch and those that improve continuously in production.
2. Data Contracts and Observability to Guard Against Silent Failures
Production AI systems rarely fail catastrophically. They fail quietly. Outputs become less accurate, recommendations drift, and decisions degrade long before alarms are triggered. The root cause is almost always the same: data instability masked as model failure.
Scalable architectures treat data as a governed interface rather than an assumed constant. Data contracts formalize what the model expects from upstream systems: schema, ranges, freshness, and semantic meaning. When these assumptions break, the system detects and responds, rather than silently adapting in unsafe ways.
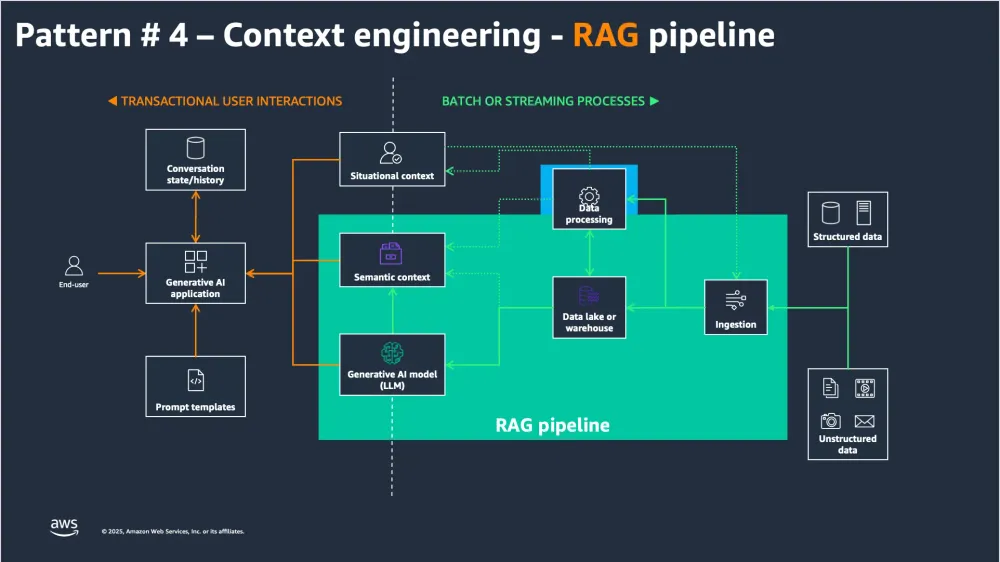
RAG pipeline architecture showing data ingestion, semantic context, and retrieval workflows (Source: AWS Generative AI reference architecture)
This pattern is critical because real-world data changes faster than models can be retrained. Business processes evolve, user behavior shifts, and upstream teams modify pipelines for unrelated reasons. Studies of deployed ML systems consistently identify data drift and pipeline instability as the dominant causes of performance degradation in production environments. When drift is invisible, teams misdiagnose problems, retrain unnecessarily, or lose confidence in AI outputs altogether.
Data contracts combined with drift detection turn data volatility from an existential threat into a manageable operational signal. They allow organizations to distinguish between model failure and data failure, which is essential for maintaining trust at scale.
3. End-to-End Versioning to Enable Accountability and Recovery
In production, the most dangerous question is one the system cannot answer: why did this decision happen? Without end-to-end versioning, AI systems become opaque under scrutiny, especially when outputs are challenged by customers, regulators, or internal stakeholders.
Scalable AI architectures enforce versioning across datasets, features, models, and deployment configurations. Every prediction can be traced back to a specific data state and model version. This capability is not about experimentation; it is about operational accountability.
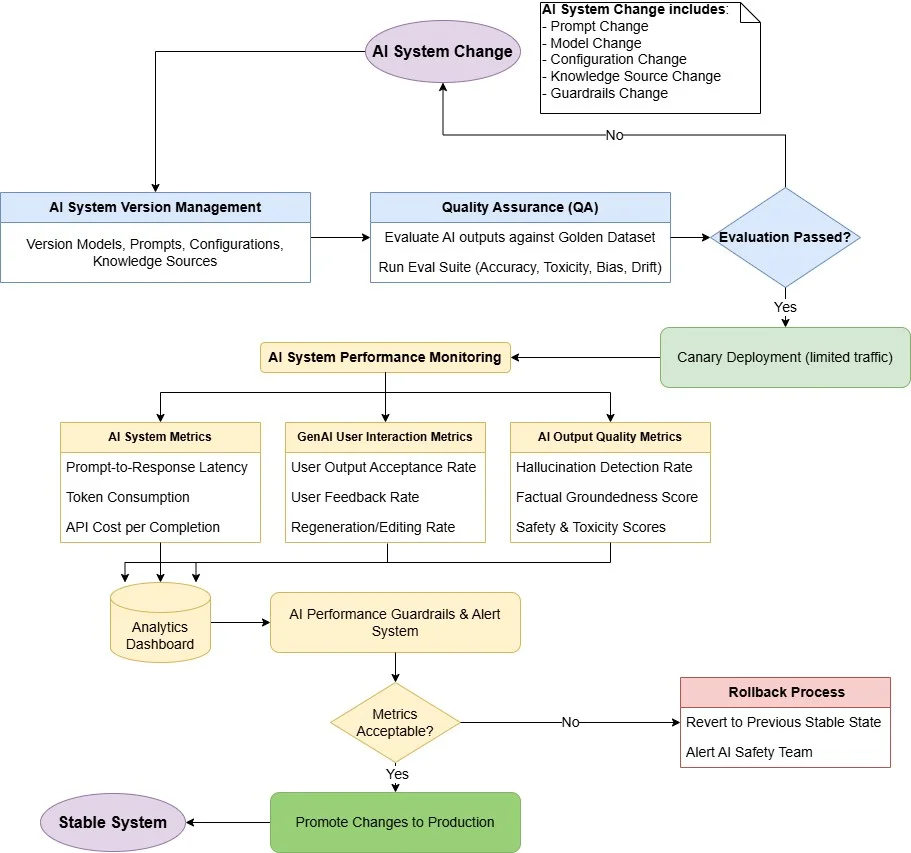
AI system lifecycle with versioning, evaluation, canary deployment, monitoring, and rollback (Source: AWS MLOps best practices)
When incidents occur, versioning enables fast root-cause analysis and safe rollback. When audits or reviews arise, it provides evidence rather than explanations. Organizations that lack this discipline often discover too late that they cannot reproduce past behavior, making it impossible to correct errors credibly or defend decisions. At scale, this erodes trust faster than any single model mistake.
4. Behavior-Centric Observability to Detect Degradation Before Failure
Traditional observability answers whether a system is running. Scalable AI systems must answer whether the system is behaving correctly. This distinction is fundamental.
Production AI rarely fails as an outage. It fails as gradual misalignment between model outputs and business reality. Input distributions shift, confidence patterns change, and downstream teams quietly compensate for declining quality. Without behavioral observability, these signals go unnoticed until the impact is material.
Architecture patterns that scale introduce observability at the behavior layer: tracking how inputs, outputs, and outcomes evolve over time, and correlating those signals with business KPIs. This allows teams to detect degradation early, intervene selectively, and avoid reactive shutdowns. As AI adoption expands across organizations, behavior-centric observability becomes the primary mechanism for maintaining reliability without freezing innovation.
5. Human-in-the-Loop as a Structural Control, Not a Fallback
In scalable AI systems, autonomy is a design choice, not a default. Fully automated decisions may be acceptable for low-impact tasks, but become dangerous when AI influences financial outcomes, compliance, or customer trust.
Human-in-the-loop (HITL) patterns define explicit boundaries where human judgment is required. These boundaries are enforced by policy, not intuition. The goal is not to slow AI down, but to contain risk where errors are costly.
Well-designed HITL architectures also create high-quality feedback loops. Human review generates labeled data in precisely the scenarios where the model is least confident. Over time, this improves performance while preserving safety. In contrast, systems that remove humans entirely often scale errors faster than they scale value.
6. Cost-Aware Inference as a First-Class Architectural Constraint
Many AI systems collapse after early success not because they stop working, but because they stop making economic sense. Inference cost scales with traffic, complexity, and retries, often faster than expected. Scalable architectures treat cost as a design constraint from the outset. They introduce routing between models based on request complexity, caching where appropriate, and graceful degradation under peak load. This prevents a common failure mode: technically successful AI systems that are quietly de-prioritized because they cannot justify their operating cost.Cost-aware design ensures that scalability aligns with business value, not just technical capability.
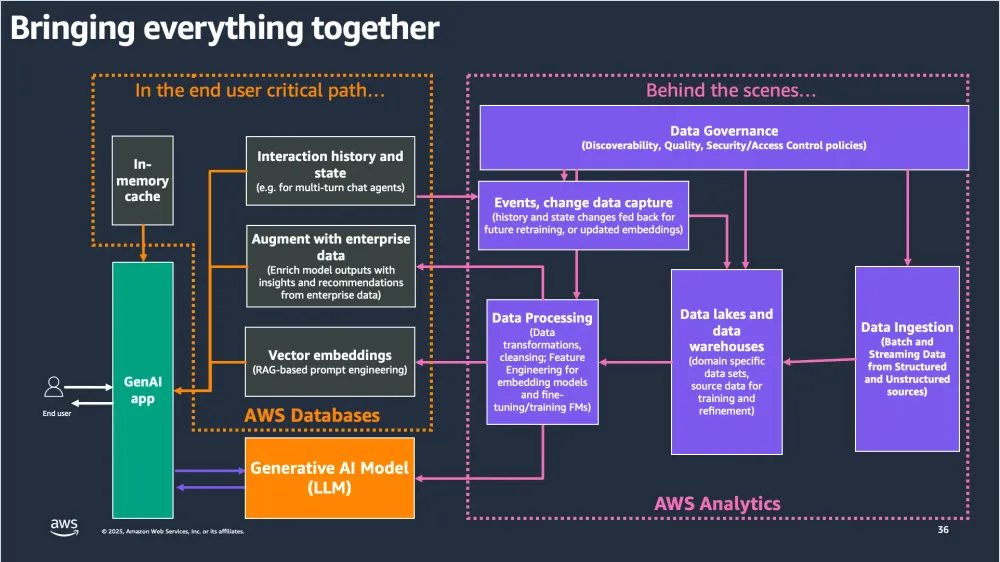
Enterprise AI architecture integrating data governance, event feedback, analytics, and model lifecycle (Source: AWS Analytics & GenAI Architecture)
Individually, each pattern addresses a specific production risk. Together, they define production-ready AI architecture: systems that can evolve, withstand volatility, and remain accountable under scale. This is the difference between AI that impresses in demos and AI that survives long enough to matter.
From Model-Centric to System-Centric AI Thinking
A model-centric mindset optimizes for demos. The objective is to prove technical feasibility quickly and address production concerns later. This approach works for experimentation, but it rarely holds up in real operations, where AI systems must handle live data, ongoing change, and business accountability.
A system-centric mindset starts from production realities. Instead of asking whether a model performs well in isolation, the focus shifts to whether the system can operate reliably over time. This means designing for stable data sources, predictable behavior under failure, early detection of silent degradation, appropriate governance for AI-driven workflows, and clear economics tied to business value rather than raw inference cost.
This shift is increasingly necessary as AI adoption outpaces operational readiness. AI usage is becoming standard across organizations, but most proofs-of-concept still fail to evolve into durable production systems. The differentiator is not model quality, but the ability to repeatedly turn pilots into systems that can be governed, scaled, and sustained.
At Twendee, we design AI systems with this production reality as the starting point. We work with enterprises to move beyond model performance and address the full operating lifecycle: data readiness, deployment architecture, observability, governance, and cost control. Our role is not to optimize a single model in isolation, but to help organizations build AI systems that behave predictably under real workloads, degrade safely under failure, and continue to deliver value as requirements evolve. By shifting from model-centric execution to system-centric architecture, AI stops being a one-off initiative and becomes a dependable part of the enterprise technology stack.
Conclusion
AI systems fail in production not because models underperform, but because the surrounding architecture is not designed for real operating conditions. Production-ready AI requires more than accuracy. It demands resilient data pipelines, controlled deployment, continuous observability, clear governance, and cost discipline aligned with business value.
Organizations that succeed with AI are those that shift from model-centric experimentation to system-centric design. They treat AI as infrastructure, not as a one-off initiative, and build architectures that can absorb change without breaking trust or control.
At Twendee Labs, we work with enterprises to design and implement production-ready AI systems grounded in real operational constraints. From architecture assessment to system redesign and deployment, we help organizations turn promising AI initiatives into scalable, governed, and sustainable production systems.
If your AI projects are delivering strong demos but struggling to scale in real environments, Twendee Labs can help evaluate your current architecture and design a system built for long-term operation.
Contact us: Twitter & LinkedIn Page
Read latest blog: New 2025 Cost Breakdown of Building a Multi-Chain Web3 Product