
Most Web2 platforms do not fail when they grow. They slow down, become expensive, and harder to change. Releases take longer, cloud costs rise, and engineering teams spend more time maintaining the system than improving it. These are not scaling side effects. They are symptoms of web2 architecture mistakes accumulating over time. The impact is measurable. Technical debt can consume 15%–60% of IT spend (McKinsey), developers already lose 17.3 hours per week to maintenance work (Stripe), and 27% of cloud spending is wasted due to structural inefficiencies (Flexera). Traffic is rarely the root cause.
This article examines the most common web2 architecture mistakes that make scaling costly and fragile, and outlines how growing platforms can reduce technical debt without disrupting production systems.
What Breaks When Platforms Grow
In growing Web2 platforms, architecture mistakes are rarely obvious design flaws. They are structural decisions that work at a smaller scale but become disproportionately costly as usage, data volume, and team size increase. These mistakes typically surface as slower release cycles, higher incident risk, rising cost-to-serve, and increasing change complexity, long before systems fail outright (McKinsey).
A common misconception is that these problems stem from choosing the “wrong” architecture pattern. In practice, most Web2 scaling failures are not caused by monoliths or microservices themselves, but by how architectural patterns behave under growth pressure. Each approach optimizes for a different phase of development and begins to break down when pushed beyond that context.
Architecture pattern under growth | Optimizes for | Breaks down when | Typical symptom |
Monolith | Fast early delivery, simple operations | Shared release risk dominates | Deployments slow, incidents cascade |
Modular monolith | Clear boundaries with shared runtime | Boundary discipline erodes | Cross-module coupling resurfaces |
Microservices | Independent scaling and deployments | Operational overhead outpaces benefits | Tool sprawl, reliability inconsistency |
The table above reframes the discussion from “which architecture is better” to “where architecture becomes a liability under growth”. This distinction is critical. Many teams attempt to solve scaling problems by changing patterns or adding infrastructure, while the underlying issue lies in unmanaged coupling, unclear domain boundaries, and workflow-fragile backend design. Understanding how different architectures fail under scale sets the foundation for identifying the most common web2 architecture mistakes explored in the sections that follow.
When the Monolith Becomes the Only Unit of Change
Monolithic architectures are not inherently flawed. In early-stage Web2 platforms, they often enable faster delivery and simpler operations by minimizing coordination overhead. The architecture mistake emerges later, when the platform grows but the unit of change remains unchanged.
As usage increases, workloads diversify and teams begin working on multiple domains in parallel. At this stage, the monolith no longer represents a single coherent system. It becomes a container for unrelated changes that must still move together. The result is not technical failure, but structural drag.
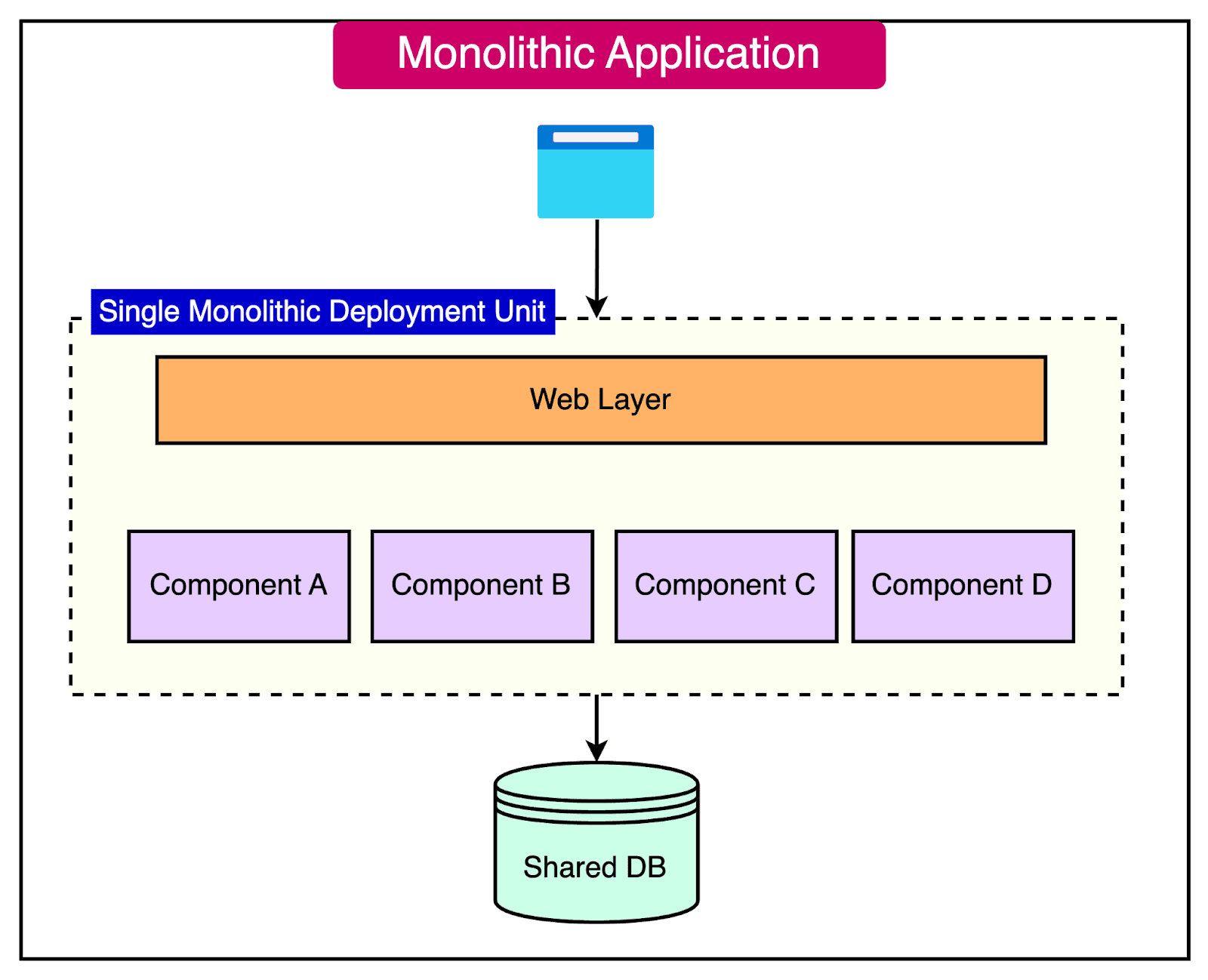
Single monolithic deployment unit causes release coupling (Source: ByteByteGo)
When a monolith becomes the only deployable unit, three structural issues appear:
Release coupling becomes unavoidable. Changes in independent domains are deployed together, forcing teams to align release schedules and delay deployment until all risks are cleared. Over time, release frequency declines not because teams slow down, but because coordination cost becomes embedded in the architecture.
Fault domains expand beyond business boundaries. Shared libraries, common data layers, and cross-cutting logic allow failures to propagate across unrelated user journeys. Incidents grow in blast radius, recovery becomes slower, and rollback decisions carry higher risk.
Scaling is applied at the wrong granularity. Performance pressure in a single workflow often leads to scaling the entire application. Localized hotspots trigger global resource increases, inflating cloud spend without addressing the underlying workload shape. This is a common reason why scaling Web2 platforms becomes disproportionately expensive.
These issues are frequently misdiagnosed as infrastructure limitations. Teams respond by adding servers, tuning autoscaling policies, or introducing more aggressive caching. While these actions may stabilize performance temporarily, they do not reduce coupling, narrow fault domains, or change the deployment unit. As a result, cost-to-serve continues to rise while delivery speed stagnates. Industry data supports this pattern. Developers already spend an average of 17.3 hours per week on maintenance and rework rather than building new features (Stripe, The Developer Coefficient). In highly coupled systems, a growing share of this time is consumed by regression testing, release coordination, and risk mitigation.
In practice, this architecture mistake shows up clearly in operational metrics. Release frequency declines even as teams grow, change failure rates increase, and cloud costs rise faster than user or traffic growth. These are strong signals that the system’s architecture no longer matches its organizational and workload complexity.
A monolith has crossed from asset to liability when independent teams cannot deploy independently, when performance issues in one domain require scaling the entire system, and when release planning becomes a cross-team negotiation rather than a routine operation. At that point, the challenge is no longer how to scale infrastructure, but how to restructure the system so that change, failure, and scaling can occur at smaller, independent units.
Backend Built Around Features, Not Workflows
As Web2 platforms grow, backend systems often expand by responding to feature requests rather than by reinforcing core workflows. This approach is efficient in the short term, but it quietly introduces a structural mismatch: the system optimizes for delivery speed, not for long-term coherence.
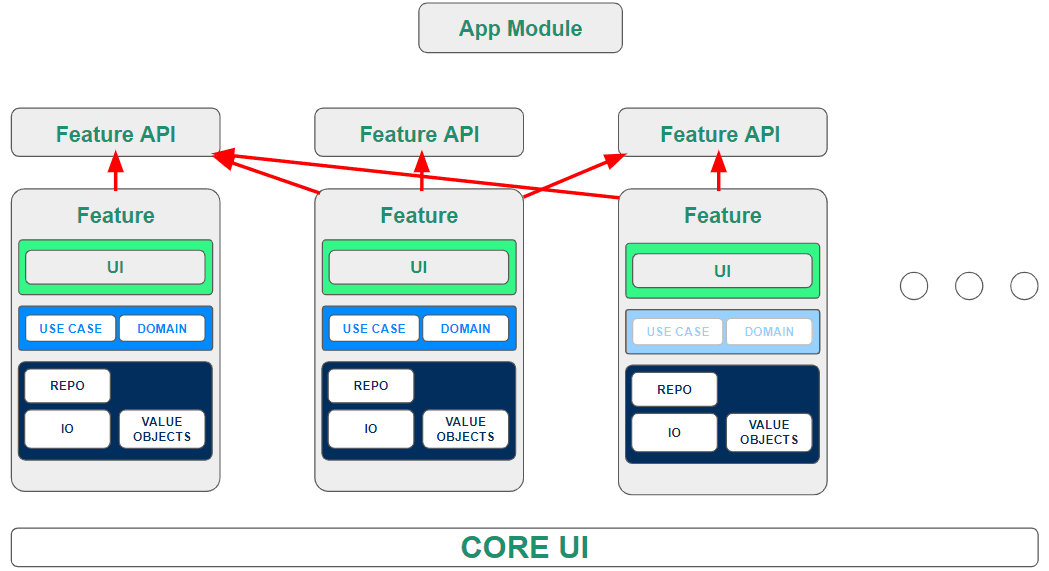
Feature-based backend fragments workflows across modules (Source: Troido.com)
Feature-driven backend growth fragments responsibility. Each new feature adds endpoints, services, or background jobs that solve a local problem, but the overall flow of data and decisions across the platform becomes harder to reason about. Over time, the backend stops reflecting how the business actually operates and instead mirrors the order in which features were shipped.When backend architecture evolves around features rather than workflows, three predictable issues emerge:
Domain boundaries erode. Multiple teams touch the same business logic from different angles. Ownership becomes implicit, and changes in one feature unintentionally affect others. This increases regression risk and slows development as teams hesitate to modify shared areas.
Data ownership becomes ambiguous. When workflows span multiple services without clear authority, the same data is read and written in multiple places. This leads to race conditions, inconsistent states, and compensating logic that grows harder to maintain over time.
Integration complexity replaces architecture clarity. Instead of clean, intentional flows, the system relies on chains of API calls, retries, and asynchronous fixes. Each new integration adds surface area for failure, increasing the operational burden without improving scalability.
The business impact of this pattern is significant. McKinsey estimates that technical debt can consume 15%–60% of total IT spend in large organizations, largely due to rework, coordination overhead, and delayed delivery (McKinsey, “Tech Debt: Reclaiming Tech Equity”). Feature-driven backend growth is one of the most common sources of this debt in Web2 systems.
From an engineering perspective, the cost shows up as lost capacity. Stripe’s Developer Coefficient report found that developers spend over 40% of their time on maintenance and rework, not on building new product value. In workflow-fragile backends, much of this time is spent tracing side effects and stabilizing integrations rather than improving core functionality.
In practice, this mistake becomes visible when backend changes feel riskier than they should, onboarding new engineers takes longer because system behavior is non-obvious, and adding features increasingly requires touching unrelated parts of the system. At that point, the backend is no longer scaling with the product; it is actively resisting it.
Scaling Infrastructure Without Fixing Core Architecture
When performance degrades under growth, infrastructure is often the first lever teams pull. Servers are added, autoscaling policies are tuned, caches are layered in, and new managed services are introduced. These actions are rational responses to immediate pressure, but they frequently mask a deeper issue: infrastructure is being used to compensate for architectural inefficiency.
In many Web2 platforms, this creates a dangerous illusion of progress. Latency improves temporarily, incidents stabilize, and the system appears healthier. Meanwhile, the underlying structure remains unchanged, and operating costs rise steadily.
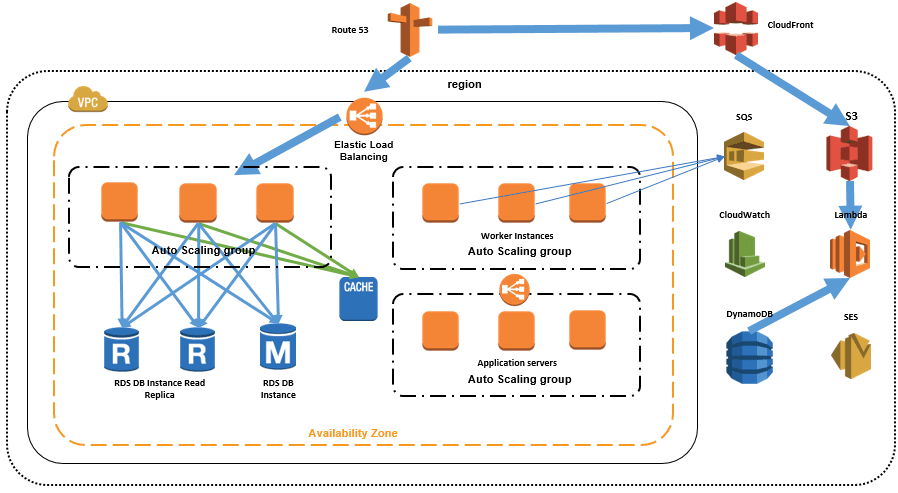
Scaling infrastructure layers without fixing core architecture (Source: AWS Startups Blog)
Scaling infrastructure without addressing architecture introduces three long-term risks:
Cost-to-serve grows faster than usage. When workloads cannot be isolated, scaling is applied broadly rather than precisely. Local bottlenecks trigger global resource increases, driving cloud spend upward without proportional business value.
Operational complexity compounds. Additional infrastructure layers require monitoring, tuning, and incident response. Each optimization adds cognitive load, increasing the chance of configuration errors and slowing recovery during outages.
Architectural debt becomes harder to unwind. The more infrastructure is added to stabilize a flawed design, the more difficult it becomes to refactor later. Teams become dependent on compensating mechanisms instead of addressing root causes.
Industry data highlights how widespread this pattern is. Flexera’s State of the Cloud report consistently shows that around 27% of cloud spend is wasted, often due to over-provisioning and inefficient architecture rather than lack of demand. This waste is not primarily a financial optimization issue; it is a structural one. From a reliability standpoint, Google’s Site Reliability Engineering research emphasizes that system complexity is a leading contributor to incidents, especially when failure domains are large and poorly isolated (Google SRE Book). Infrastructure-heavy mitigation strategies tend to increase, not reduce, this complexity.
The warning signs are usually clear. Cloud costs rise faster than traffic or revenue, performance improvements require increasingly aggressive tuning, and outages become harder to diagnose despite better tooling. At this stage, scaling Web2 platforms becomes a question of sustainability rather than capacity. The critical insight is that infrastructure scaling cannot fix architectural coupling. It can only postpone its consequences. Sustainable scale requires restructuring workflows, narrowing failure domains, and aligning system boundaries with how the business actually operates.
How to Evaluate Architecture Before It Breaks Scale
When a Web2 platform begins to feel heavier under growth, teams often respond by optimizing around the edges: tuning infrastructure, adding tooling, or reorganizing delivery processes. These efforts can delay visible failure, but they rarely change the trajectory. The more important question is whether architecture itself has become misaligned with scale.
At this stage, scaling problems no longer appear as simple capacity shortages. They surface as systemic signals that are both observable and measurable:
Cost-to-serve rises faster than usage or revenue, indicating that additional load requires disproportionately more resources.
Release cycles slow down, even as engineering headcount increases, revealing embedded coordination cost.
Operational risk increases, with incidents affecting wider portions of the system and taking longer to resolve.
These patterns are not anecdotal. Industry research shows that technical debt can consume 15%–60% of total IT spend in large organizations (McKinsey). Developers already lose 17.3 hours per week on average to maintenance and rework instead of building new functionality (Stripe, Developer Coefficient). At the infrastructure level, around 27% of cloud spend remains wasted due to inefficiencies rather than demand (Flexera, State of the Cloud).
When these signals appear together, they point to architecture as the constraint rather than execution. The system’s unit of change has grown too large, workflows are fragmented across unclear boundaries, and infrastructure is increasingly used to compensate for structural limitations.
In practice, this inflection point becomes clear when:
Independent teams can no longer deploy independently without elevated risk.
Performance issues in one domain trigger system-wide scaling responses, inflating cost without solving root causes.
Operating costs rise while delivery speed stagnates, indicating that optimization is masking deeper issues.
Addressing this misalignment does not require a full rewrite. Effective platforms focus on reducing architectural friction by narrowing failure domains, clarifying data ownership, and aligning system boundaries with real business workflows. These interventions lower the cost of change and restore delivery velocity without disrupting production systems. This is why sustainable scale in Web2 environments begins with architectural evaluation, not migration. By identifying where architecture amplifies cost and risk, teams can intervene selectively, reduce technical debt, and regain control over growth before structural inefficiencies become entrenched.
Conclusion
Most Web2 platforms struggle at scale not because of traffic, but because architecture decisions made for speed gradually turn into structural debt. As systems grow, release coupling widens, workflows fragment, and cloud costs rise without restoring delivery velocity. At that point, technical debt becomes a permanent operating cost.
Twendee works with Web2 teams at this exact inflection point. The focus is not on replacing systems that already work, but on evaluating existing architecture under growth pressure. This typically involves mapping end-to-end workflows, identifying release and failure coupling, analyzing cost-to-serve drivers, and surfacing hidden technical debt that slows delivery or inflates cloud spend. From there, Twendee helps design targeted restructuring paths such as boundary realignment, workflow refactoring, or selective decoupling that reduce technical debt while keeping production systems stable.
This approach allows engineering teams to regain control over change. Delivery velocity improves because risk is localized. Operating costs stabilize because scaling is applied precisely, not globally. Most importantly, architecture evolves in step with the organization, rather than lagging behind it.
For teams feeling increasing friction as their Web2 platform grows, the next step is not more tooling or capacity. It is understanding where architecture has become the constraint.
Stay connected with us via Facebook, X, and LinkedIn.
Read our latest blog here: How Long Does It Actually Take to Integrate ERP with Modern Web Apps?