
Everyone wants AI inside their product until the moment real customer data touches the pipeline. That’s where excitement turns into hesitation, because the true challenge isn’t model accuracy, it’s production AI privacy. In a demo, you can call a public API and move fast; in production, you need to guarantee data never escapes your trust boundary. The companies winning with AI now aren’t just building smart features, they're building privacy-safe systems that deliver value without leaking sensitive information. The question isn’t “How do we add AI?” anymore. It’s “How do we ship AI without risking customer data?” This is how the teams doing it right are approaching the problem.
Control Data Exposure Before Anything
Protecting data in a production AI system starts with controlling what the model is allowed to see. This sounds simple, but it’s the most common place teams get it wrong. When moving from a prototype to a real product, many engineers simply feed entire chat logs, CRM notes, support tickets, or documents into the model. The idea is “more context makes the AI smarter.” In reality, it mostly increases the risk of leaking customer information without delivering meaningful accuracy gains.The right principle is straightforward: The model should only receive the minimum data required for the task no more.

Data anonymization and synthetic dataset workflow for secure AI input (source)
To make this work, you need a preprocessing layer before the model. Any personally identifiable information (PII): names, emails, phone numbers, account IDs, payment details should be masked or anonymized before being passed to the LLM. If a piece of text can reveal who a customer is, it needs to be redacted or replaced with a placeholder. The goal is not to strip context, but to make sure the model understands the task without seeing raw sensitive data.
Logging also needs to change once you’re in production. During early testing, storing raw text logs is convenient for debugging. But in real environments, raw logs containing customer data become a major leak risk. The correct approach: log masked and sanitized data, and only keep what you need to monitor system behavior, not full sensitive content.
Run Models in A Private Boundary
Once data exposure is minimized, the next layer of protection comes from where the model runs. In prototypes, sending text to a public API is common. But production AI is different: you don’t control the network, the logs, the telemetry, or the retention policies of third-party systems. No matter how confidently vendors declare “we don’t store your data,” privacy-first engineering assumes one rule: If customer data leaves your trust boundary, you must treat it as potentially exposed.
That’s why production AI privacy requires moving away from “send data out and hope it’s handled safely” toward executing inference inside a controlled environment. For high-sensitivity use cases, that boundary needs to be your infrastructure not someone else’s.
In practice, this translates into deploying models via on-prem inference or inside a private cloud VPC. Instead of routing data to a public LLM endpoint, requests stay inside your internal network, where encryption, storage, access policies, and logs are governed by your security posture. This doesn’t mean abandoning modern models; many vendors now support private gateways or enterprise-grade isolation, so organizations can use frontier-level models without exposing customer information to public infrastructure.
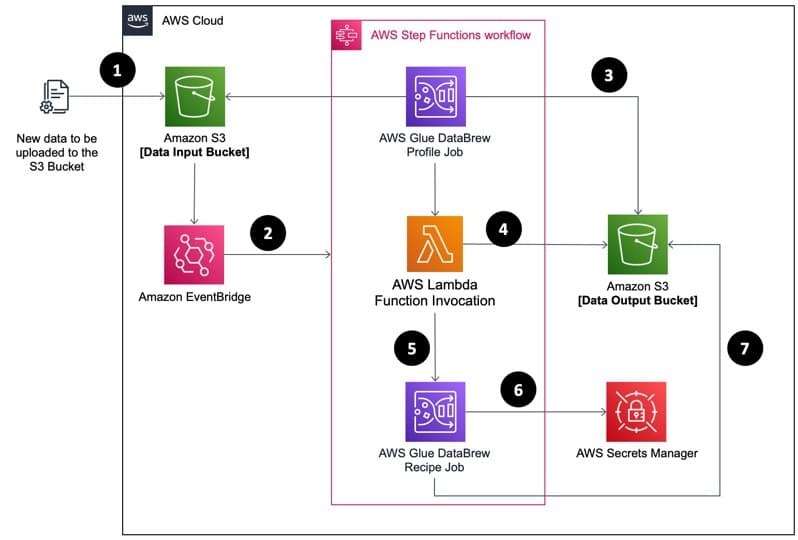
Private VPC AI deployment with secure data flow and serverless orchestration (source)
A privacy-first model deployment strategy typically means:
Running LLM inference on-prem for high-risk workloads
Using VPC endpoints instead of public API calls
Ensuring no customer data hits public networks
Encrypting in-transit and at-rest traffic within your environment
Auditing inference traffic like any internal microservice
At scale, this architecture isn't just about compliance, it becomes a strategic moat. Teams avoid future legal constraints, minimize operational risk, and prevent vendor lock-in tied to data policies. They also control infrastructure costs more effectively, avoiding fragmented AI deployments and tool sprawl that quietly drains budget and slows delivery. If you want a deeper breakdown on this point, see our guide on how to stop AI sprawl from wasting your development budget
When model execution stays inside your network boundary, you’re not just protecting data, you're building an infrastructure where trust, compliance, and innovation can scale together. AI becomes a secured capability, not a liability waiting to surface.
Secure the Prompt & Output Layer
Even with private deployment and masked inputs, the language interface remains one of the biggest risk surfaces in production AI. A prompt is not just text, it is an entry point attackers can manipulate. Users can attempt jailbreaks, bypass system rules, or extract sensitive context the model has seen. Likewise, model responses are not harmless strings: without safeguards, they can unintentionally reveal private details or internal knowledge.
LLMs are optimized to be helpful, not secure. They do not inherently understand confidentiality boundaries; they only optimize for the “best possible answer”. This is why protecting this layer is not about hoping the model behaves correctly, it is about building guardrails around the behavior. Prompts must be treated like API inputs, with validation and injection defenses. Outputs must be scanned before reaching users, ensuring the model never echoes sensitive content. And fine-tuning must be handled carefully; feeding raw customer data into training effectively teaches the model to “remember” information it should never retain.
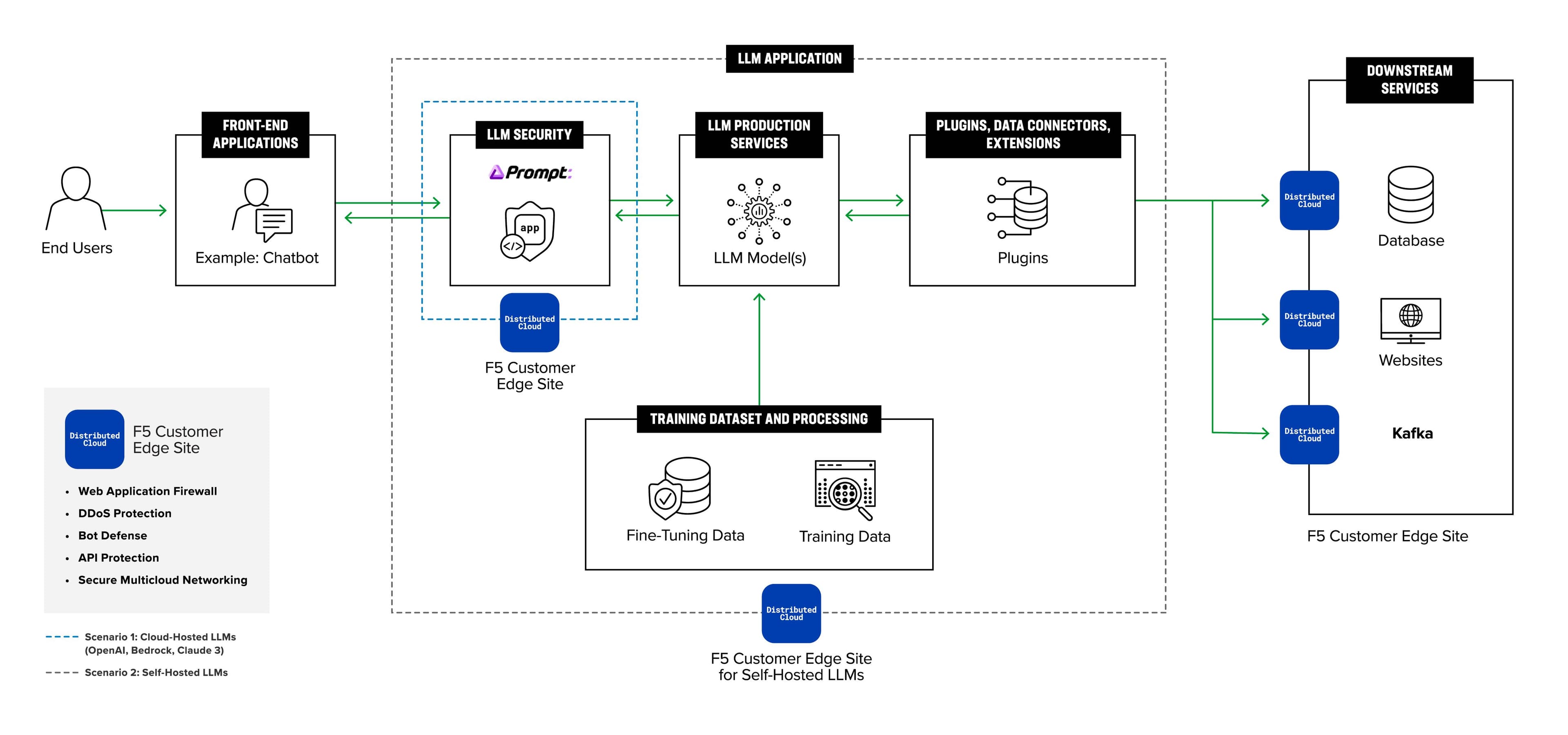
Enterprise LLM security architecture with private inference boundary, prompt firewall, and controlled data flows (source)
A secure production system typically:
Uses a “prompt firewall” to block jailbreak and injection attempts
Scrubs PII from responses before returning them to the user
Prevents the model from repeating sensitive context it was shown
Redacts data when fine-tuning never trains on raw customer text
Monitors model behavior to detect unusual or policy-violating outputs
When prompts and outputs are treated as security boundaries not creative text fields the system shifts from a demo mindset to real-world reliability. This layer determines whether AI merely works, or whether it works safely, consistently, and trustably in front of customers.
Build RAG With Governance, Not Blind Indexing
Retrieval-augmented generation (RAG) is becoming the default way to give AI access to internal knowledge. But in production, it is also one of the easiest ways to leak sensitive information at scale. The worst mistake teams make is treating RAG like a storage bucket dumping all internal files, knowledge bases, chats, and docs into a vector database and letting the model search freely. That isn't knowledge engineering; it’s uncontrolled data exposure with an AI front-end.
Enterprise RAG must behave like a database with permissions, not like a shared drive. The system should know which user is asking, what data they are allowed to see, and which knowledge sources are approved for AI usage. The vector store itself must enforce isolation: different teams, data classes, and sensitivity levels cannot all live in one pool. And ingestion must filter, classify, and redact information rather than ingesting raw text simply because “AI might need it someday.”
A governed RAG pipeline typically:
Indexes only approved and permission-scoped content
Applies RBAC so retrieval matches the requester’s actual access rights
Encrypts vector data and separates namespaces by function or department
Logs retrieval events for accountability and auditability
Supports source citation or reference links, so answers are attributable not hallucinated
Good RAG design mirrors secure data access design: you don’t give every employee full database access, and you shouldn’t give an AI model full knowledge access either. The purpose is not to feed the model “as much as possible,” but to feed it exactly what it is allowed to know, no more, no less and to prove that access control works. When teams implement RAG this way, AI becomes a safe amplification layer on top of enterprise knowledge not a risk multiplier. It respects the same trust boundaries as your internal systems, which is the only viable path for production deployments.
Observability & Kill-Switch for Safety
Even with strict data controls, private inference, and governed RAG, a production AI system is never “finished.” Models evolve, prompts change, user behavior shifts, and edge cases emerge. The only reliable stance is to assume that something unexpected will eventually happen and build the ability to detect, trace, and shut down harmful behavior before it becomes a breach.
In traditional engineering, observability means latency, throughput, and error rate. In AI, it also means privacy behavior, understanding how the system handles sensitive information in real time. This requires a monitoring layer that sees not only the system metrics, but also the “semantic behavior” of the model: what it tries to say, what users attempt to make it say, and whether responses stay within policy boundaries.
Auditability matters too. When a compliance officer or security lead asks, “Who accessed what, and why?” your AI platform must answer clearly. That means tracing prompts and responses but tracing them safely, without storing raw sensitive data. Metadata, masked logs, intent signals, and retrieval records are enough to ensure accountability without creating new leak surfaces.Finally, no production AI system is complete without a kill-switch. It should be possible to isolate the model, disable inference, or fall back to a deterministic system when anomalies arise. AI is probabilistic and adaptive which is why responsible AI engineering includes a deterministic escape hatch.
A production-ready setup typically includes:
Real-time monitoring for abnormal or potentially sensitive outputs
Masked logging and metadata-only traces to avoid leak-prone logs
Alerts for jailbreak attempts, PII resurfacing, or policy violations
A kill-switch or fallback flow when the model crosses safety boundaries
Periodic red-team testing and behavior audits to validate system integrity
This layer shifts AI from “working most of the time” to “working reliably under uncertainty.” The goal is not paranoia, it's professionalism. When your system can observe itself, explain its decisions, and shut itself down if needed, AI becomes an asset you can trust, not a risk you hope to contain.
Conclusion
The real test of AI isn’t in a prototype, it’s in production, where data is real, stakes are high, and trust becomes a competitive advantage. Accuracy matters, but in the enterprise, integrity matters more. Every organization can build an AI feature. Few can build one that protects the people behind the data, withstands scrutiny, and scales without compromise. Production AI privacy is not a constraint, it's an architecture choice. When teams limit exposure, keep inference inside controlled boundaries, enforce guardrails around language behavior, govern knowledge access, and instrument systems with observability and fail-safe controls, AI shifts from novelty to infrastructure. It becomes something an executive can sign off on not an experiment sitting one incident away from rollback.
Most leadership teams today understand what secure AI should look like: private inference, masked data flows, access-controlled RAG, and audit-ready operations. The real challenge isn’t knowing the principles; it’s executing them with precision at production scale. That’s where we operate. At Twendee, we design and deploy secure AI architectures that protect data by default, not by exception. We build private LLM stacks, structured knowledge pipelines with enforced access boundaries, and compliance-aligned workflows that allow AI to operate with trust and accountability from day one.
If your organization is moving toward production-grade AI and needs a partner who treats privacy, control, and reliability as engineering standards not optionalTwendee, we’re here to support the journey. Let’s build AI that you can deploy confidently and stand behind long term. Follow Twendee for more insights and implementation practices across AI architecture, security, and enterprise deployment and connect with us on LinkedIn, X, and Facebook to explore how we’re shaping secure AI adoption in real-world environments.