
ost organizations believe they understand how their systems operate. Architecture diagrams exist. Process flows are documented. Ownership is assigned. Yet when a critical incident occurs, the same question surfaces across teams: where exactly did the business flow break? The problem is not a lack of tools or effort. It is that end-to-end system visibility quietly disappears as systems evolve faster than shared understanding. When visibility collapses, risk accumulates invisibly until failure forces the organization to rediscover how its systems actually work.
Why end-to-end system visibility erodes long before failures appear
In most enterprises, the loss of end-to-end system visibility does not happen overnight. It accumulates gradually through structural decisions that make sense locally, but create blind spots globally. Three factors consistently explain why organizations lose sight of how their systems actually work together.
1. System fragmentation turns business flows into invisible chains
Modern enterprises run core operations across CRM, ERP, identity services, payments, data pipelines, internal APIs, and third-party vendors. Each system is owned and optimized separately, but no single team owns the end-to-end business flow.
Fragmentation typically accumulates through:
M&A and platform expansion, where integration stops at basic connectivity
Local tool choices that solve team-level problems but ignore system-wide impact
Third-party dependencies that sit outside direct operational control
Urgent integrations built for speed and never fully normalized
Over time, each system carries part of the logic, while understanding of how those parts interact steadily erodes.
The risk is delayed visibility. Local signals remain healthy while the overall process degrades quietly. When failure surfaces, it feels sudden, even though the causes have existed for months.
Industry benchmarks show that short periods of unplanned downtime can already translate into hundreds of thousands or millions in losses. In many cases, the dominant cost is not the outage itself, but the time spent identifying where the business flow actually broke.
2. Monitoring answers system questions, not business questions
Most organizations have strong monitoring and observability at the system level. Metrics, logs, and alerts provide detailed visibility into individual components. What they rarely provide is clarity at the level incidents actually demand.
During major incidents, teams are not asking whether a service is up. They are trying to understand how business execution is failing across systems. Research shows that outage impact is increasingly measured by duration, making time-to-understanding a primary cost driver (SINTEF).
This shift explains why delayed diagnosis now accounts for a disproportionate share of outage cost across large enterprises.
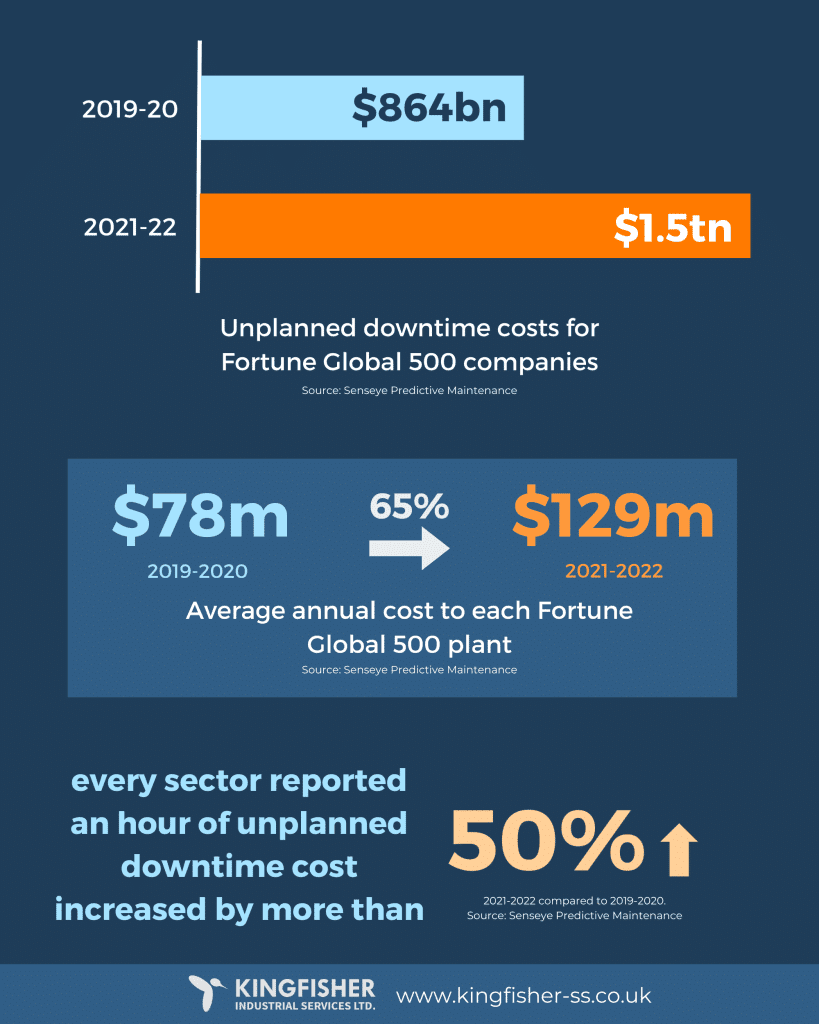
Unplanned downtime cost growth driven by outage duration (Source: Kingfisher)
In practice, teams struggle to answer:
Which business flows are failing right now
Where the first break occurs across systems
Which downstream processes are at risk next
What change or data condition triggered the cascade
These are questions of business process visibility, not infrastructure health. Dashboards optimized for uptime and latency rarely capture execution paths, handoffs, or dependency chains.
As a result, incident response often begins with reconstruction. Teams piece together logs, dashboards, and tribal knowledge to rebuild an understanding of the flow before meaningful remediation can begin. Every minute spent reconstructing reality compounds outage cost.
3. Visibility collapses at the system boundaries where execution actually happens
Distributed systems engineering addressed many observability limits by introducing tracing techniques that follow requests across services. Within tightly controlled engineering environments, this works well.
In enterprise contexts, however, execution rarely stays within a single traceable domain. Critical steps often occur at boundaries that traditional tracing cannot fully capture:
SaaS platforms outside internal instrumentation
Batch jobs and scheduled processes detached from request lifecycles
Manual approvals and human-in-the-loop decisions
Third-party services with opaque failure behavior
This complexity is not abstract. Large enterprises now operate across an average of 900+ applications, yet less than 30% of them are integrated in a way that supports end-to-end business execution (ONEiO Cloud).
At these boundaries, visibility collapses where business risk is highest. Systems may appear healthy, but they no longer explain whether the business outcome is actually being achieved.
This creates a common paradox: systems are operational, yet customers cannot complete critical workflows. The issue is rarely a single outage. It is the breakdown of execution across loosely connected systems.
Without a model that links systems, dependencies, and data flows into a coherent execution view, organizations remain reactive. They see symptoms first, and structure only after an incident forces it into view.
What end-to-end system visibility really means in fragmented enterprises
End-to-end system visibility is often mistaken for better dashboards or more telemetry. In fragmented enterprises, the real issue is not data availability, but the lack of control over how business outcomes are produced across systems.
In practice, this visibility only exists when execution, dependency, and data flow remain aligned. When they drift, incidents become harder to diagnose and change becomes inherently risky.
1. Execution truth replaces documented intent
Most organizations rely on process documentation to explain how work should happen. In reality, documentation captures intent, while execution evolves through exceptions, retries, manual workarounds, and system-specific logic. Over time, the documented flow and the running flow diverge.
True visibility starts when execution itself becomes the source of truth.
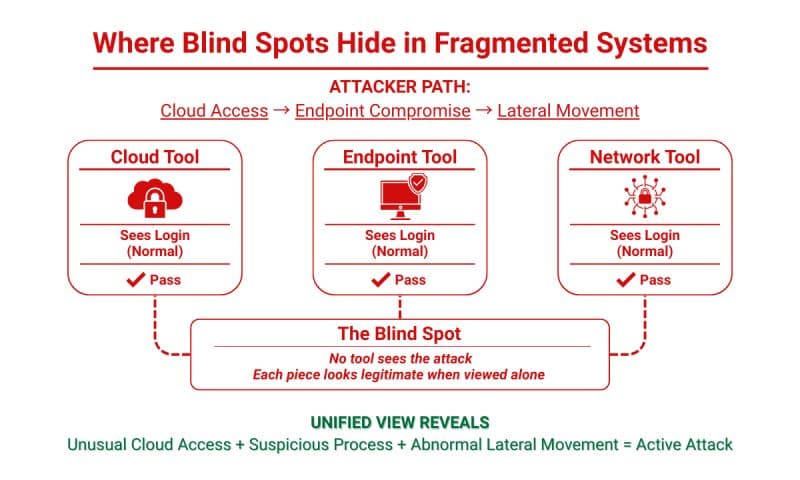
Blind spots formed when systems are monitored in isolation. (Source: Seceon)
In practice, this means:
Mapping how work actually flows across systems, not how it was designed
Treating exception paths and retries as normal behavior, not edge cases
Accepting that undocumented steps often carry the highest operational risk
This is where architecture analysis becomes necessary. No single internal team sees the full execution path across applications, integrations, and vendors. Twendee typically supports organizations at this stage by analyzing the current architecture and reconstructing real end-to-end workflows based on how systems actually operate, not how they were originally documented.
2. Dependency truth shifts focus from systems to outcomes
Even when execution paths and dependencies are understood, visibility collapses if data loses meaning as it moves. Identifiers drift, schemas change quietly, and transformations accumulate without clear ownership. Data continues to flow, but its semantic integrity degrades across hops.
This is why many failures occur without any system appearing unhealthy. APIs respond successfully. Pipelines complete. Jobs finish on schedule. Yet business outcomes become inconsistent or incorrect because the data that connects systems no longer carries the same meaning end-to-end.
End-to-end system visibility therefore depends on disciplined data-flow design, not just connectivity:
Stable identifiers that survive system boundaries and allow correlation across services
Explicit ownership of data contracts and transformations, rather than implicit assumptions
Consistent context propagation so execution can be traced as a single flow, not isolated events

End-to-end trace context propagation across services. (Source: OpenTelemetry)
Without these controls, observability signals explain activity but not correctness. Teams can see that something happened, but cannot confidently explain whether it happened as intended. Investigation turns into manual reconciliation across logs, payloads, and system-specific identifiers.
Standardizing data flows does not reduce flexibility. It creates a shared baseline where change becomes predictable. When data meaning is preserved across systems, organizations can reason about impact before changes reach production, rather than discovering mismatches after business outcomes are already affected. This is the layer where architecture analysis, workflow mapping, and data normalization converge, enabling systems to evolve without silently breaking end-to-end execution.
Conclusion
Most organizations lose control not because systems fail, but because they no longer understand how business outcomes are produced across fragmented systems. When execution, dependencies, and data flows drift out of alignment, visibility disappears long before incidents become obvious.
End-to-end system visibility is therefore an architectural control discipline, not a monitoring upgrade. It determines whether change can be reasoned about safely or only discovered after damage occurs. As expectations toward technology partners evolve, clarity across systems is becoming a baseline capability rather than a differentiator, as outlined in what businesses expect from technology partners in 2026.
Twendee supports organizations in analyzing architectures, mapping real end-to-end workflows, and standardizing data flows so visibility enables control, not guesswork. Learn more at Twendee, or follow ongoing insights on LinkedIn and Facebook.